|
特点 |
实现 |
适用于 |
不适用于 |
|
表结构 |
建表时确定列 |
规范格式数据(如:报表) |
异性(非规范结构)数据,扩展性不够,比如:爱好 |
|
数据完整性 |
范式、约束、事务…… |
高标准要求正确性 |
无需严格检查数据正确性 |
|
高可查询性 |
索引、丰富的SQL语句 |
读大于写 |
写大于读 |
典型场景:汽车监控系统
大致经历一下三个阶段:
体会:工程中的“中庸”,不追求纯粹……
目前NoSQL数据库最广泛的用法:作为“缓存(复习:人人都是程序员)层”使用。
Windows上演示,需要下载windows安装包。
命令格式都一样:
set {key} {flags} {exptime} {bytes} [noreply]
set yz 1 30 5 //存储 键yz 标记1 30秒,占用5个字节 nosql //键yz对应的值为nosql
其他的命名语法格式和set相同,只是命令关键字不一样:
get
delete
可以查看memcached的状态,最常用的几个指标:
stats后面还可以再跟
小技巧:中文输入法
Redis 官方不建议在 windows 下使用 Redis,所以官网没有 windows 版本可以下载。
和memcached非常类似,通常配合在Java框架中用于做分布式缓存层。
暂略。
其实从严格意义上来讲,开发人员对数据库的性能优化是无能为力的。
因为他们唯一的手段:写出更好的SQL语句,由于执行计划的存在,很多时候也是不可控的。
包括建立索引、设置事务隔离级别,这些手段严格来说,都是DBA的工作(或权限)。
但面试的时候,开发人员也常常被问起“数据库优化”的问题,所以
是解决性能问题性价比最高的手段。
但是,怎么堆?
水平扩展:增加服务器的数量
垂直扩展:增加服务器的质量
但不要因为现在普遍采用的是水平扩展的方式,就认为没有垂直升级的必要。很多时候,垂直升级还是最优解,一般是要垂直升级升不动(性价比低)了,才考虑水平升级。
@想一想@:为什么?方便呀,^_^
读一台服务器,写一台服务器。
读服务器自动的向写服务器更新。(实现技术:主从备份)
主要是解决很多应用“读远大于写”的问题,不让读/写互相拖累。
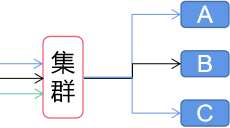
多台服务器一起工作,但对外表现为像一台服务器一样(对外透明)。
如果说读写分离对客户透明,也可以认为他们就是一种集群。
但一般认为集群是通过“负载均衡”进行任务分配的,且任务不区分读写。
当我们着重强调群君和分布式区别的时候,可以这样理解:
集群只强调多台服务器对外透明,很多时候每一台服务器上(节点)的数据是一致的,任何一个节点宕掉都只影响性能不影响可用性(集群的高可用性)
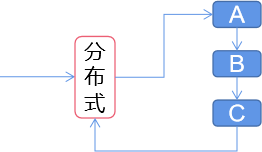
分布式强调分散的部署,很可能不同的服务器部署不同的内容,完成某一项工作有可能需要多个节点配合才能完成,一个节点宕掉可能导致整个工作无法完成(@想一想@:既然如此,为什么还要分布式?单个节点的容量到达上限,图片的分布式存储)
 |
 |
为了解决分布式的问题,可以在分布式的节点上布置集群。
可以认为是DBA的日常工作:在资源恒定的情况下,让数据库有更好的性能表现(performance)。
是性能调优的基础。DBA通常需要获得一些关键的数据:
然后配合性能优化方法论,找到瓶颈,设计方案,不断测量。
纵向拆分,比如:
横向拆分,比如:文章表的标题/正文/作者/发布时间基本上是恒定的,但赞/踩经常更新,当他们在一张表的时候,赞/踩的更新(假设)会加行锁,就会影响到标题/正文等的读。所以我们可以
但这样的操作,必然影响到业务逻辑的正常实现,只能是(类似于故意违反范式引入冗余的)非常规手段。
尽可能多的写出“查找每个用户关键字最多的求助” 的SQL语句,利用执行计划,找出效率最高的一个。
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

