为演示方便,再引入Score和Bed类,自此:
@ManyToMany(mappedBy = "students") private Set<Teacher> teachers = new HashSet<>(); @ManyToMany private Set<Student> students = new HashSet<>();
@OneToMany(mappedBy = "candidate") private List<Score> scores = new ArrayList<>(); @ManyToOne private Student candidate;
@OneToOne(mappedBy = "sleepedBy") private Bed bed; @OneToOne private Student sleepedBy;
Student atai = new Student("atai", true, 17, DayOfWeek.MONDAY, LocalDate.of(2011, 5, 1),
new Contact("atai@qq.com", "178654321"), "我是阿泰,泰山的泰,^_^");
Student bo = new Student("bo", true, 16, DayOfWeek.TUESDAY, LocalDate.of(2011, 6, 1),
new Contact("bo@qq.com", "158654322"), "我是波仔,鱼仔的仔");
Student lang = new Student("lang", false, 21, DayOfWeek.FRIDAY, LocalDate.of(2011, 5, 18),
new Contact("lang@qq.com", "148654323"), "我是浪神,女神的神……");
Teacher fg = new Teacher("fg");
Teacher xy = new Teacher("xy");
Score aSQL = new Score("SQL",atai, 85.0f);
Score aJava = new Score("Java",atai, 90.0f);
Score bSQL = new Score("SQL",bo, 85.0f);
Score bJava = new Score("Java",bo, 78.5f);
Score bJavascript = new Score("JavaScript",bo, 82.5f);
Score lSQL = new Score("SQL",lang, 78.0f);
Score lCSharp = new Score("CSharp",lang, 86.0f);
Score lJava = new Score("Java",lang, 55.5f);
Bed aBed = new Bed("闭包间", atai); Bed lBed = new Bed("二叉树", lang);
fg.getStudents().add(atai);
fg.getStudents().add(bo);
xy.getStudents().add(bo);
xy.getStudents().add(lang);
em.persist(fg); em.persist(xy); em.persist(bo); em.persist(atai); em.persist(lang); em.persist(aBed); em.persist(lBed); em.persist(aSQL); em.persist(aJava); em.persist(bSQL); em.persist(bJava); em.persist(bJavascript); em.persist(lJava); em.persist(lCSharp); em.persist(lSQL);
默认的,当我们加载一个entity的时候,除了集合以外,它的其他
@想一想@:关联属性怎么及时加载?log演示:使用JOIN
Student atai = em.find(Student.class, 1); //SELECT ???
//基本属性
System.out.println(atai.getAge());
System.out.println(atai.getName());
System.out.println(atai.getEnroll());
//ValueType
Contact contact = atai.getContact();
System.out.println(contact.getEmail());
//关联属性
Bed bed = atai.getBed();
System.out.println(bed.getId());
System.out.println(bed.getName());
//集合:以下那一句语句执行时会查询数据库?
System.out.println(atai.getTeacher() == null);
Set<Teacher> teachers = atai.getTeacher();
System.out.println(teachers.size());
for (Teacher teacher : teachers) {
System.out.println(teacher.getName());
}
但关联属性和集合的加载方式可以通过在注解中设置属性值fetch予以改变:
@ManyToMany(mappedBy = "students", fetch = FetchType.EAGER)
log演示:SELECT中主动的JOIN
但是,当出现一对一的双向链接时,如果我们是从inverse的一段设置到owner的关联lazyload
@OneToOne(mappedBy = "sleepedBy", fetch = FetchType.LAZY) private Bed bed;我们的自定义就会失效。
log演示:首次加载就出现两次SELECT,第一次SELECT不涉及bed,第二次就JOIN Bed……
@想一想@:为什么呢?
因为lazyload需要Id!Student表里没有Bed的Id,Hibernate无法构建proxy对象。
演示:从Bed到Student就可以lazyload。
已有两个entity,我们要在其间添加关联。
注意:如之前演示,双向引用一定要在owner一端添加(实际开发中就总是在两端添加即可)
直接进行设置就可以了:
Student lang = em.find(Student.class, 3); Bed bed = em.find(Bed.class, 2); //合乎双向关联规则的(可省略) lang.setBed(bed); //起决定作用的 bed.setSleepedBy(lang);
本质上是一条UPDATE语句,但我们却额外执行了两条SELECT语句,@想一想@:是不是不值?
这里使用session.load()或em.getReference()也没有用,因为:所有的lazyload,在使用setter的时候必然查询数据库(演示:略)
但是,如果省略掉lang.setBed(bed);可以少一个有关lang的SELECT语句。
Teacher fg = em.getReference(Teacher.class, 1); Student lang = em.getReference(Student.class, 3); //会通过SELECT...JOIN加载出fg的students集合 fg.getStudents().add(lang); //一样会SELECT...JOIN,但作为inverse端,可省略 lang.getTeachers().add(fg);
一样出现了没有必要的SELECT。
而且在加载students的时候,会依次查询Student的Bed(因为关联属性引用)
@想一想@:如果是重复的添加,会有什么样的结果?
当使用Hibernate的时候,集合用List还是Set,某些时候会对SQL的生成产生影响。比如我们将teachers和students都改成List:
@ManyToMany private List<Student> students = new ArrayList<>(); @ManyToMany(mappedBy = "students") private List<Teacher> teachers = new ArrayList<>();
首先,关系表不再有主键了(演示)
然后,当我们添加一个关联时,神奇的事情发生了:
delete
from
Teacher_Student
where
teachers_id=?
Hibernate会先将之前的关联全部删除,然后再重新写入!为什么会这样?因为这是List,List中没有为每个元素本身进行“标记”,所以集合元素会被各种魔改:删了又加,加了又改,……,最后flush的时候,Hibernate将此时的集合和最初加载时的snapshot比较,已经无能为力(非常麻烦)了,比如这样:
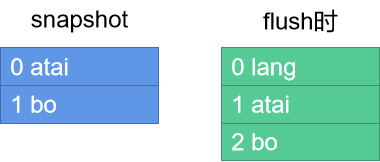
@想一想@:你会怎么比对这两个List集合,确定相应的增删改?注意:你一定是要比较元素本身(而不是下标)的,这种比较有可能是极其耗时的。
但Set不一样,因为它是有键值确保元素唯一的,它就可以用唯一键方便快速比对。
推荐:条件允许的话,还是使用Set吧。
实际开发中通常都是在生成一(端entity)的同时就建立了一对多的关联并持久化。以下仅为演示用:
先准备一个“无主的”Score:
Score lHtml = new Score();
lHtml.setName("HTML");
em.persist(lHtml);
em.flush();
再添加关联关系:
Student lang = em.getReference(Student.class, 3); //因为setter,会SELECT...FROM Student lHtml.setCandidate(lang); //这里“不”会额外SELECT哟,赞! //inverse端,可省略 lang.getScores().add(lHtml); //生成UPDATE语句 em.flush();
@想一想@:为什么一对多时可用不用SELECT集合,多对多就必须要SELECT?
如果从性能优化的角度考虑,要慎用(不是说不能用):
首先考虑是不是可以用ValueType代替,因为ValueType的加载不需要外键JOIN。
然后考虑是不是可以使用一对多替换,这倒无关性能,而是为未来扩展提供可能性。比如现在一个学生一张床,但以后呢?源栈同学出栈入栈,一定会形成一(张床)对多(个学生)的关系。
实际上,必须要用一对一关联,而不能使用ValueType或一对多关系的例子是非常非常少的。
首先,要搞清楚owner端和inverse端非常麻烦(尤其是没有annotation,而是xml配置的时候);
不想搞清楚,蒙着头写,就得两端同步,造成性能上的损耗。
尤其是一对一的双向引用:默认采用eager load模式,所以inverse的一端始终无法proxy load,就会JOIN查询,非常没有必要。
所以每当你要引入集合的时候,仔细思考:有无必要?是不是entity不可或缺的一部分?比如:汽车的轮胎,就是不可或缺,缺了汽车没法跑;老师的学生就不一定是不可或缺的,没了学生的老师还可以是老师。具体到代码层面,就是没有这个集合,我这个entity就没办法实现某个功能,那这个集合就是必须的,比如老师有一个点名的功能……
你清楚的知道这样做会带来的问题,仔细权衡之后你仍然觉得这样做,那一般来说都是OK的。
引入一个关系表对应的entity:
@Entity
public class Student2Teacher implements Serializable {
@Id
@ManyToOne
private Student student;
@Id
@ManyToOne
private Teacher teacher;
说明:
Student和Teacher分别反向(inverse)引用这个关系entity:
@OneToMany(mappedBy = "student") private Set<Student2Teacher> teachers = new HashSet<>();
@OneToMany(mappedBy = "teacher") private Set<Student2Teacher> students = new HashSet<>();
添加关联时之前的:
fg.getStudent().add(atai);就要变成:
em.persist(new Student2Teacher(atai, fg));于是我们就可以独立的操作这个关系entity(比如INSERT)
log演示:仅仅在flush()时生成一条INSERT语句
以下不深究SELECT相关的性能,只关注:
Student lang = em.find(Student.class, 3); //注意owner和inverse端的区别 lang.getBed().setSleepedBy(em.find(Student.class, 1));;
update Bed set name=?, sleepedBy_id=? where id=? binding parameter [2] as [INTEGER] - 1
Score score = em.find(Score.class, 1); score.setCandidate(null);
update Score set name=?, candidate_id=?, point=? where id=? binding parameter [2] as [INTEGER] - [null]
从面向对象的角度,集合是可以替换的,比如要交换atai和lang的成绩:
Student atai = em.find(Student.class, 5); Student lang = em.find(Student.class, 6); atai.setScores(lang.getScores()); //行不行?
注意:这样做的结果是让atai和lang“共享”一个Scores集合,而不是lang的Scores给atai,lang自己还有一个副本啥的……(复习:值类型和引用类型)
而且,在我们的映射关系中,一对多的集合端,是inverse的一段不是owner一段,在上面的操作是不会对数据库生效的!
PS:基于同样的原因,如果ORM严格遵守JPA规范,add()/remove()等都不会生效。
所以我们还是得在集合中迭代:
//lang的成绩挨个重新设置考生atai
for (Score score : lang.getScores()) {
score.setCandidate(atai);
}
//再把atai的成绩挨个设置考生为lang
atai.getScores().stream().forEach(s->s.setCandidate(lang));
@想一想@:第一个foreach结束之后,atai.getScore()会不会在原基础上增加?为什么?
这时候有一个集合在owner端,就可以对数据库产生实质性的影响了。
但基于和“一对一”一样的原因,交换我们就省略了。我们演示:
//xy老师本来的学生是4和6 Teacher xy = em.find(Teacher.class, 4); //想改成5和6 HashSet<Student> newStudents = new HashSet<>(); newStudents.add(em.find(Student.class, 5)); newStudents.add(em.find(Student.class, 6)); xy.setStudents(newStudents);演示:Hibernate先删除(DELETE)再添加(INSERT)
Student atai = em.find(Student.class, 1); Teacher fg = em.find(Teacher.class, 1); fg.getStudents().remove(atai);理解:atai不再是fg的学生,fg不再是atai的老师,不能说atai就没了……
在Hibernate里面,也可以通过annotation进行设置。
比如给某个床位设定一个Student:
em.find(Bed.class, 1).setSleepedBy( new Student());
如果没有cascade:
Caused by:
org.hibernate.TransientPropertyValueException: object references an
unsaved transient instance - save the transient instance before flushing
: Bed.sleepedBy -> Student
意思是说:new出来的student还是transient的,不能直接flush。要是不用cascade,代码得这样写:
Student student = new Student(); em.persist(student); em.find(Bed.class, 3).setSleepedBy(student);
显得比较麻烦,所有可以直接在Bed中设置:
@OneToOne(cascade = CascadeType.PERSIST) private Student sleepedBy;
演示:生成INSERT Student语句
演示:删除一个学生呢?
Student lang = em.find(Student.class, 1); em.remove(lang);
报错:(注意:如果接着上面的代码演示,没有删掉sleepedBy上的cascade就完全不一样了)
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Cannot delete or update a parent row: a foreign key constraint fails (`17bang`.`teacher_student`, CONSTRAINT `FK_Teacher_Student_students_id_Student` FOREIGN KEY (`students_id`) REFERENCES `student` (`id`)
理解:cascade本质上还是以外键约束为基础的(复习:SQL中自带的cascade功能设置)。但Hibernate喜欢使用这种表述:删除父类对象的时候,如何处理子类对象……
@想一想@:删除Bed和Score呢?会不会造成cascade?
所以需要设置:
@ManyToMany(mappedBy = "students", cascade = CascadeType.REMOVE) private Set<Teacher> teachers = new HashSet<>();
演示:还需要继续设置所有相关联的Bed和Score……以及灾难性的结果:
该删的(Bed和Score)不该删的(Teacher)都删了。
演示:没有设置cascade的时候,删除一个老师
Teacher fg = em.find(Teacher.class, 3); em.remove(fg);
可以看到,Hibernate会自动在删除老师的同时(之前),删除掉该Teacher和Student的关联。
如果我们加上CascadeType.REMOVE,他就会cascade到删除学生的entity!
log演示SQL: delete from Student ……
PS:还有其他的CascadeType,用得不多:略首先,不能在@ManyToMany上设置cascade;
然后,通过Student找到他的所有Teacher,在Teacher端删除和这个Student的关联:
lang.getTeachers().forEach( t->t.getStudents().removeIf( s->s.getId() == lang.getId()));log演示:delete from Teacher_Student
标记当一个entity成为孤儿时自动删除,在JPA 2.0中引入,可以通过annotation进行标记:
@OneToOne(mappedBy = "sleepedBy", orphanRemoval = true) private Bed bed;
演示:从运行效果上来看,它和CascadeType.REMOVE非常类似。
但是,两者的差别非常非常微妙。StackOverflow高赞回答说……
然鹅,还是要cacade才会触发orphanRemoval。
演示:直接把Bed的SleepBy设置成NULL看看有没有用?
飞哥能想到的例子:在一对多的关系中,删除集合中某一个元素
Student lang = em.find(Student.class, 6); //本来,Student作为inverse一端,对其集合的操作是无法持久化到数据库的 lang.getScores().remove(0);
但如果我们进行如下设置:
@OneToMany(mappedBy = "candidate", //两个都必须要有 cascade = CascadeType.PERSIST , orphanRemoval = true ) private List<Score> scores = new ArrayList<>();
就能够实现删除第一条成绩的效果。(log演示:DELETE语句)
为什么呢?其(生硬的)逻辑如下:
这一章节的内容,非常容易被滥用。
稍有不慎,它就会:
同学们在使用的时候,务必小心小心再小心。
多快好省!前端后端,线上线下,名师精讲
更多了解 加:

